CountBio
Mathematical tools for natural sciences
Biostatistics with R
Read and write table data in R
The data used for statistical analysis is generally written in a tablular format and saved in one of the formats like excel sheet (.xls file extension), csv file (comma separated) or text file (tab or space separated). These files can be read into R as data frames using library functions.
Reading an excel table into R
Consider the following excel file called "model_data.xls", whose screen shot is shown below:
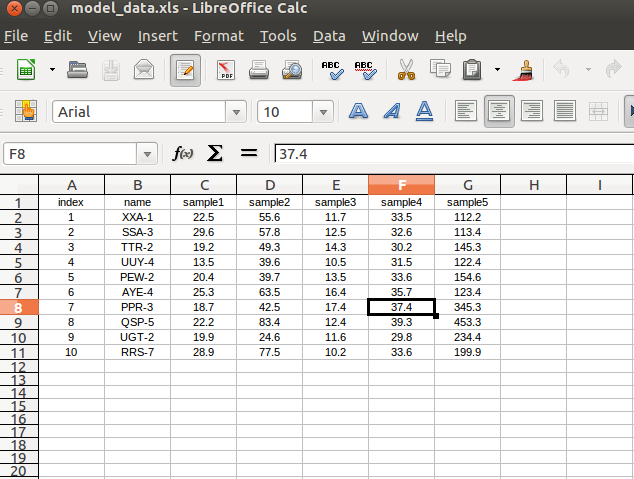
We can read this into R as a data frame using
To use this function, the install the gdata library from R prompt with the command, > install.packages("gdata") This is an one time installation.
A call to the
## Reading data from excel sheet. library(gdata) dat = read.xls(xls="model_data.xls", sheet=1, blank.lines.skip=TRUE) print(names(dat)) dat$sample1
In the above call, sheet=1 refers to the first sheet, and blank.lines.skip=TRUE skips empty rows in the data.
After this, 'dat' is treated like any other data frame in R. See help(read.xls) to learn about more features of this function.
Reading table data from a csv file
For reading data from a file with comma separated data, we use read.csc() function in R.
We will now read the following table data stored in a csv file called "model_data.csv" using "read.csv()" function.
index,name,sample1,sample2,sample3,sample4,sample5 1,XXA-1,22.5,55.6,11.7,33.5,112.2 2,SSA-3,29.6,57.8,12.5,32.6,113.4 3,TTR-2,19.2,49.3,14.3,30.2,145.3 4,UUY-4,13.5,39.6,10.5,31.5,122.4 5,PEW-2,20.4,39.7,13.5,33.6,154.6 6,AYE-4,25.3,63.5,16.4,35.7,123.4 7,PPR-3,18.7,42.5,17.4,37.4,345.3 8,QSP-5,22.2,83.4,12.4,39.3,453.3 9,UGT-2,19.9,24.6,11.6,29.8,234.4 10,RRS-7,28.9,77.5,10.2,33.6,199.9
The code below shows how to read the above file into a data frame:
# Reading data from csv file dat = read.csv(file="model_data.csv", header=TRUE) print(names(dat)) dat$sample1 mean(dat$sample1)
The option header=TRUE tells the function that the first row of the data should be treated as column names.
Reading data table from a tab or space separated text file
The data from tab or space separated text file can be read into a data frame using read.table() function of R. We will now read the following space separated data in a file called "model_data.txt" :
index name sample1 sample2 sample3 sample4 sample5 1 XXA-1 22.5 55.6 11.7 33.5 112.2 2 SSA-3 29.6 57.8 12.5 32.6 113.4 3 TTR-2 19.2 49.3 14.3 30.2 145.3 4 UUY-4 13.5 39.6 10.5 31.5 122.4 5 PEW-2 20.4 39.7 13.5 33.6 154.6 6 AYE-4 25.3 63.5 16.4 35.7 123.4 7 PPR-3 18.7 42.5 17.4 37.4 345.3 8 QSP-5 22.2 83.4 12.4 39.3 453.3 9 UGT-2 19.9 24.6 11.6 29.8 234.4 10 RRS-7 28.9 77.5 10.2 33.6 199.9
The code below is self explanatory. We can also use an additional parameter sep="\t" for reading tab separated files. The function can also detect space or tab separator without 'sep parameter.
## Reading data from blank or tab separated text file dat = read.table(file="model_data.txt", header=TRUE) print(names(dat)) mean(dat$sample1)
Writing a data frame into a text file
To write a data frame in R into a text file, we use
We will create a data frame and write it into a file. Code is here:
## Reading data from blank or tab separated text file dat = read.table(file="model_data.txt", header=TRUE) print(names(dat)) mean(dat$sample1) ## Writing a data frame into text file names = c("aaa","bbb","ccc","ddd","eee","fff") col1 = c(1121, 1344, 2354, 4676, 2256, 4534) col2 = c(122.5, 324.6, 456.3, 457.3, 845.1, 325.8) col3 = c(45, 56, 67, 75, 34, 89) datframe = data.frame(names, col1, col2, col3) ## writes the data frame into a tabs separated text file, without row numbering write.table(datframe, file="model_table.txt", sep="\t", row.names=FALSE)
Now if we edit the file "model_data.txt", it will contain the following data:
"names" "col1" "col2" "col3" "aaa" 1121 122.5 45 "bbb" 1344 324.6 56 "ccc" 2354 456.3 67 "ddd" 4676 457.3 75 "eee" 2256 845.1 34 "fff" 4534 325.8 89