CountBio
Mathematical tools for natural sciences
Biostatistics with R
One sample t test
This test is applied to the case when we sample data points from a population which follows a normal distribution, or near normal distribution and the population varince is unknown. The n data points \(\small{x_1,x_2,.....,x_n} \) are assumed to be the random samples from a Gaussian (or near Gaussian) distribution of mean \(\small{\mu}\) and a unknown standard deviation \(\small{\sigma}\). When the population variance is unknown, the t statistic computed from the mean \(\small{\overline{x} }\) and standard deviation \(\small{s}\) of n random samples from a normal or near normal distribution follows a t distribution with n-1 degrees of freedom: \(~~~~~~~~~~~~~~~~~~~~~ \small{t = \dfrac{\overline{x} - \mu}{\left(\dfrac{s}{\sqrt{n}}\right)} = t(n-1) }\) We proceed with the hypothesis testing as follows:
- We first compute the sample mean \(\small{\overline{x}}\) from the data.
- Knowing the value of mean \(\small{\mu}\) and the computed standard deviation \(\small{s}\) of the sample, we compute the value of t using above expression.
- The statistical significance (also called "p-value") of this data is then obtained by computing the probability \(\small{P(\gt t) }\) or \(\small{P(\lt -t })\) from the t distribution. Under the null hypothesis, the p-value represents the probability of getting the observed statistic t.
- If the p-value is either smaller than a pre-decided value \(\small{\alpha}\) or the observed t statistic is outside a given range (\(\small{-t_0 \leq t \leq t_0) }\), we reject the null hypothesis and accept the alternate hypothesis. Here, \(\small{t_0}\) is the value of statistic above which the area under the unit normal curve is \(\small{\alpha}\).
- We can also reject the null hypothesis if the computed t statistic for the data is outside the \(\small{(1-\alpha)100\%}\) confidence interval on the population mean.
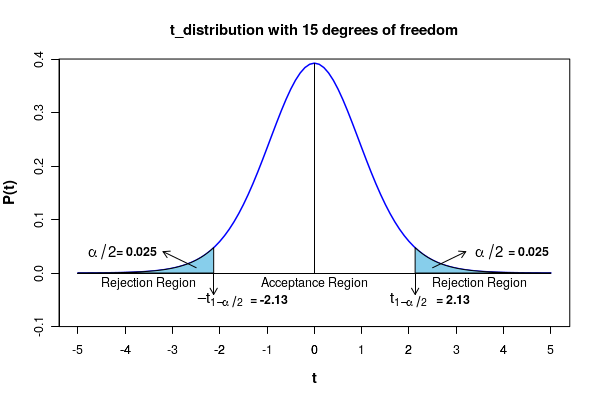
Since the computed value of t statistic t = -0.907 is in the acceptance region, we accept the null hypothesis to conclude that population mean of package weight is not significantly different from 100 grams. The statistical significance of this test is 0.05.
Testing the null hypothesis by computing the p-value for the observation: If the null hypothesis is true, what is the probability of getting the computed t statistic?. This probability is called the"p-value" of the observed test statistic. For the computed t value of -0.907, the p-value is obtained from the t distribution table corresponding to 15 degrees of freedom to be \(\small{p = 0.189 }\). This is the area under the curve to the left of \(\small{Z =-0.907 }\). Since the p-value \(\small{p=0.189 }\) of the observed test statistic is more than \(\small{\alpha/2 = 0.025}\), we accept the null hypothesis to a significance level of 0.05.In general, for a 2 sided test, we reject the null hypothesis if \(\small{p \leq \alpha/2 }\). If \(\small{p \gt \alpha/2 }\), we do not reject the null hypothesis.
Testing the null hypothesis by computing the confidence interval: For a significance level \(\small{\alpha = 0.05}\), the $95\%$ two sided confidence interval(CI) for the population mean is given by, \(~~~~~~~~~~~~\small{CI~=~\overline{x} \pm t_{0.975} {\dfrac{s}{\sqrt{n}} }}\). Substituting \(\small{\overline{x}=99.1,~~~~s=3.97,~~~~n=16}\) from the data and \(~\small{t_{0.975}(15)~=~2.13}~\) from the t table for 15 degrees of freedom, we get a $95\%$ confidence interval of \(\small{CI = 99.1 \pm 2.13*\dfrac{3.97}{\sqrt{16}}= 99.1 \pm 2.11 = (97.0, 101.2)}\) Since this $95\%$ confidence interval \(\small{(97.0, 101.2)}\) contains the sample mean 99.1, we accept the null hypothesis at the level of 0.05 and conclude that the population mean for the weight of the pack is \(\small{\mu = 100~grams}\).
R-scripts
The R script given below performs the one sample t test. Given a data set x that is assumed to be randomly drawn from a Gaussian distribution of population mean mu and standard deviation sigma, the function returns the conclusions of the test along with computed statistic values.
The function is defined as,one_sample_t_test(x, muzero, alpha, null) wherex = data vectormuzero = population mean for comparisonalpha = significane levelnull = string value indicating type of null hypothesis. Possible values of variable null are:"equal", "less_than_or_equal", "more_than_or_equal" The function returns a vector with two numbers :(p value, t statistics) .
################################################## ## One sample t test ## x = vector of data samples, which are numbers ## muzero = population mean for comparison ## alpha = significance level for testing ## null = string with three possible values "equal", "greater_than_or_equal", "less_than_or_equal" for indicating whether the test is one sided or two sided. one_sample_t_test = function(x, muzero, alpha, null ){ ## compute sample mean xbar = mean(x) ## comput sample standard deviation s = sd(x) ## get the sample size n = length(x) ## compute the t statistic t_statistic = (xbar - muzero)/(s/sqrt(n)) ## compute the p-value pvalue = 1.0 if(t_statistic > 0) pvalue = 1 - pt(t_statistic, n-1) if(t_statistic < 0) pvalue = pt(t_statistic, n-1) if(t_statistic == 0) pvalue = 0.5 ## Perform the statitical test by comaring the computed t statistic with the ## critical value for various cases ### Case 1 : Null hypothesis that populatin mean equals a given value if(null == "equal") { t_critical = qt(1 - (alpha/2), n-1) print("################################################################") print("One sample t test : ") print(paste("sample size = ", n)) if( (t_statistic > t_critical) | (t_statistic < -t_critical) ) { print("One sample t test : ") print(paste("sample size = ", n)) print(paste("Null hypothesis is rejected at the level of significance ", alpha/2)) print(paste("Population mean not equal to ", muzero)) print(paste("p value for the test = ", pvalue)) print(paste("Value of t statistic = ", round(t_statistic, digits=2))) print(paste("Critical value of the test = ", round(t_critical, digits=2))) resultVec = c(pvalue, round(t_statistic, digits=2)) } if( (t_statistic < t_critical) & (t_statistic > -t_critical) ) { print("One sample t test : ") print(paste("sample size = ", n)) print(paste("Null hypothesis is accepted at the level of significance ", alpha/2)) print(paste("Population mean equal to ", muzero)) print(paste("p value for the test = ", pvalue)) print(paste("Value of t statistic = ", round(t_statistic, digits=2))) print(paste("Critical value of the test = ", round(t_critical, digits=2))) resultVec = c(pvalue, round(t_statistic, digits=2)) } } ##### Case 2 : Null hypothesis that population mean is less than or equal to a given value if(null == "less_than_or_equal") { t_critical = qt(1 - alpha, n-1) print("################################################################") print("One sample t test : ") print(paste("sample size = ", n)) if( t_statistic > t_critical ) { print("One sample t test : ") print(paste("sample size = ", n)) print(paste("Null hypothesis is rejected at the level of significance ", alpha)) print(paste("Population mean greater than ", muzero)) print(paste("p value for the test = ", pvalue)) print(paste("Value of t statistic = ", round(t_statistic, digits=2))) print(paste("Critical value of the test = ", round(t_critical, digits=2))) resultVec = c(pvalue, round(t_statistic, digits=2)) } if( t_statistic <= t_critical ) { print("One sample t test : ") print(paste("sample size = ", n)) print(paste("Null hypothesis is accepted at the level of significance ", alpha)) print(paste("p value for the test = ", pvalue)) print(paste("Value of t statistic = ", round(t_statistic, digits=2))) print(paste("Critical value of the test = ", round(t_critical, digits=2))) resultVec = c(pvalue, round(t_statistic, digits=2)) } } ###### Case 3 : Null hypothesis that the population mean is less than or equal to a given value. if(null == "greater_than_or_equal") { t_critical = qt(1 - alpha,n-1) print("################################################################") print("One sample t test : ") print(paste("sample size = ", n)) if( t_statistic < t_critical ) { print("One sample t test : ") print(paste("sample size = ", n)) print(paste("Null hypothesis is rejected at the level of significance ", alpha)) print(paste("Population mean is less than ", muzero)) print(paste("p value for the test = ", pvalue)) print(paste("Value of t statistic = ", round(t_statistic, digits=2))) print(paste("Critical value of the test = ", round(t_critical, digits=2))) resultVec = c(pvalue, round(t_statistic, digits=2)) } if( t_statistic >= t_critical ) { print("One sample t test : ") print(paste("sample size = ", n)) print(paste("Null hypothesis is accepted at the level of significance ", alpha)) print(paste("p value for the test = ", pvalue)) print(paste("Value of t statistic = ", round(t_statistic, digits=2))) print(paste("Critical value of the test = ", round(t_critical, digits=2))) resultVec = c(pvalue, round(t_statistic, digits=2)) } } return(resultVec) } ## end of the function ###############------------------------------------------------ ## Perform a sample test with the function ## define a data set x = c(96.0, 104.0, 99.1, 97.6, 99.4, 92.8, 105.6, 97.2, 96.8, 92.1, 100.6, 101.5, 100.7, 97.3, 99.6, 105.9) ## mean to be compared muzero = 100 ## alpha value alpha = 0.05 ## call the function. "res" is a vector with p-vlue and t value for the test. res = one_sample_t_test(x, muzero, alpha, "equal") print(res)
Executing the above script in R prints the following results and figures of probability distribution on the screen:
[1] "################################################################" [1] "One sample t test : " [1] "sample size = 16" [1] "One sample t test : " [1] "sample size = 16" [1] "Null hypothesis is accepted at the level of significance 0.025" [1] "Population mean equal to 100" [1] "p value for the test = 0.199101040706245" [1] "Value of t statistic = -0.87" [1] "Critical value of the test = 2.13" >